

Intro to Normalization & Standardization
Getting started with Normalization & Standardization in Data Science

Data preprocessing is a crucial step in preparing data for analysis and machine learning. There are two important techniques for dealing with numerical data: normalization and standardization. In this guide, I will explain these concepts, how they differ, and when to use each method.
Introduction to Normalization vs. Standardization
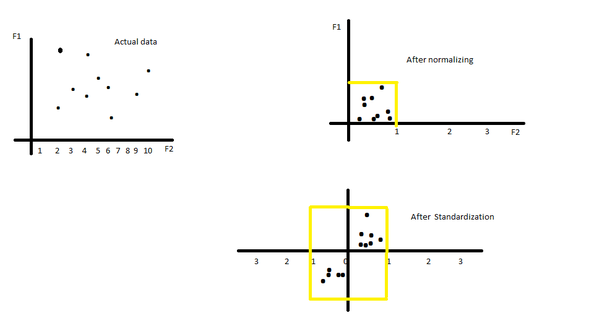
What’s Normalization: Normalization is the process of scaling the data in a feature to a specific range, usually between 0 and 1. This is done by subtracting the minimum value of the feature from each data point and then dividing by the range (the difference between the maximum and minimum values).
The formula for Min-Max normalization:
X_normalized = (X - X_min) / (X_max - X_min)Where X is a data point, X_min is the minimum value and X_max is the maximum value.
What’s Standardization: Standardization (also known as z-score normalization) transforms data so that it has a mean of 0 and a standard deviation of 1. This is achieved by subtracting the mean of the feature from each data point and then dividing it by the standard deviation.
The formula for Standardization (z-score normalization):
X_standardized = (X - mean) / std_devReason for Variables Normalization vs. Standardization
Normalization: Normalization is a way to make sure that different features in your dataset play nicely together, especially when they have very different ranges. Let's say you have two features: age, which goes from 0 to 100, and income, which ranges from 0 to maybe 100,000 or more. Income is way bigger than age. This can cause problems in some analyses, like linear regression. It might make income seem more important just because it's larger, even if it's not. So, we normalize the data to make everything fit on the same scale.
Standardization: Standardization is like putting different measurements on the same measuring stick, so they play fair in analyses. When measurements use different units or have big differences in their values, it can mess up our analysis. For example, a measurement from 0 to 1000 will have way more influence than one from 0 to 1, even if it's not actually more important. Standardization levels the playing field, making the measurements comparable. It's like making them all speak the same language, so no one gets an unfair advantage in the analysis.
When To Normalization / Standardization Variables
Normalization: Normalization is handy when you're not sure how your data is spread out or if it doesn't follow a bell curve pattern (like a typical Gaussian distribution). It's especially useful when your data has different ranges, and you're using algorithms that don't care about how the data is shaped, like k-nearest neighbours and artificial neural networks.
Standardization: Standardization works better when your data is shaped like a bell curve(Gaussian distribution), but it doesn't have to be a perfect fit. It's particularly helpful when your data has different scales, and you're using algorithms that assume your data looks like a bell curve, such as linear regression, logistic regression, and linear discriminant analysis.
Normalization and Standardization Key Differences
● Normalization makes data fit within a specific range, like 0 to 1 or -1 to 1, which is handy when our data doesn't follow a particular pattern.
● Standardization, on the other hand, is used when data behaves like a bell curve (Gaussian distribution) and centres it around zero, without fixing it to a particular range.
● Normalization is quite sensitive to extreme values, while standardization is less bothered by them.
● Finally, we use normalization when our analysis doesn't rely on any specific data assumptions, whereas standardization is chosen when our analysis assumes a Gaussian-like data shape.
FAQs
1. Are normalization and standardization the same?
No, they're different. Standardization involves subtracting the mean and dividing by the standard deviation, while normalization scales data to a range like 0 to 1.
2. Should I normalize or standardize my data?
Use normalization when your data varies greatly in scale and your analysis doesn't assume a specific data distribution. Use standardization when your data is expected to follow a Gaussian distribution.
3. Does normalization improve accuracy?
Yes, it makes your data consistent and more accurate, especially in databases where it groups similar information into a common format.
4. Which is better, normalization or standardization?
Standardization is often preferred over normalization because it handles outliers better, whereas normalization can make outliers problematic.
Your support is invaluable
Did you like this article? Then please leave a share or even a comment, it would mean the world to me!
Don’t forget to subscribe to my YouTube account HERE, Where you will get a video explaining this article!