

EDA with Pandas Profiling Package
Improve your exploratory analysis process with pandas profiling.

Are you trying to find a simple and efficient way to better comprehend your data? Pandas Profiling may be the solution for you!
Pandas Profiling is a useful tool for data analysis, especially if you're using Python and the Pandas package. It uses your dataset to produce an in-depth report. Your data are summarized, represented, and displayed in this report.

Whether you're a data scientist, an analyst, or curious about your dataset, Pandas Profiling is a valuable tool. It makes it easier and more informative to explore your data and it also generates reports that can be saved as separate HTML and JSON files.
Now, let's do an exploratory analysis of our data with Pandas Profiling.
Relevant Links
Installing Package
To get started, let’s use a command to install the Pandas Profiling package.
pip install pandas-profilingImporting Libraries and Dataset
Now, let's bring in our Pandas libraries and load our dataset. For this guide, we'll be working with a dataset called "Heart_failure_clinical_records."
# Importing Libraries
import pandas as pd
from pandas_profiling import ProfileReport
#Importing Dataset
df = pd.read_csv("/content/Heart_failure_clinical_records_dataset.csv")
df.head(
Using Pandas Profiling for EDA
To conduct Exploratory Data Analysis (EDA) using a profile report, we'll use a command called "ProfileReport" on our dataset. Afterwards, we'll save the generated report as an HTML file.
profile = ProfileReport(df, title="Heart Failure EDA Report")
profile.to_notebook_iframe()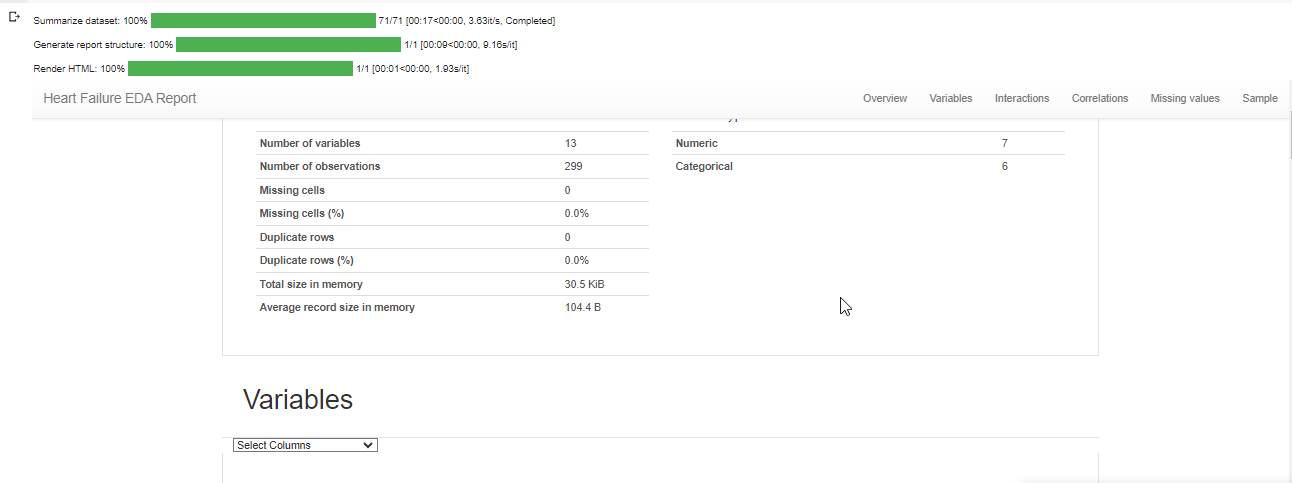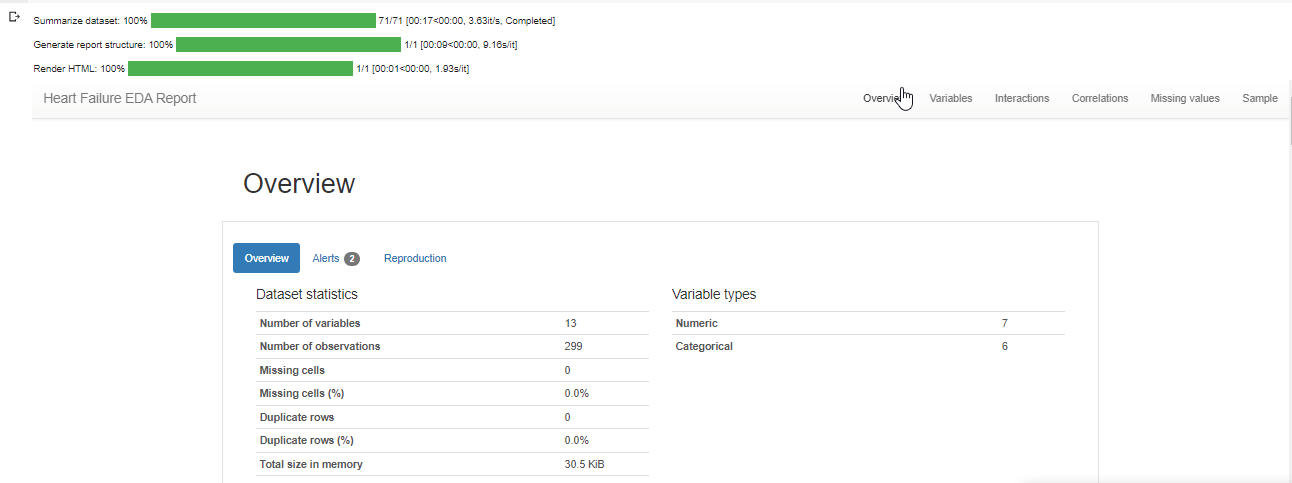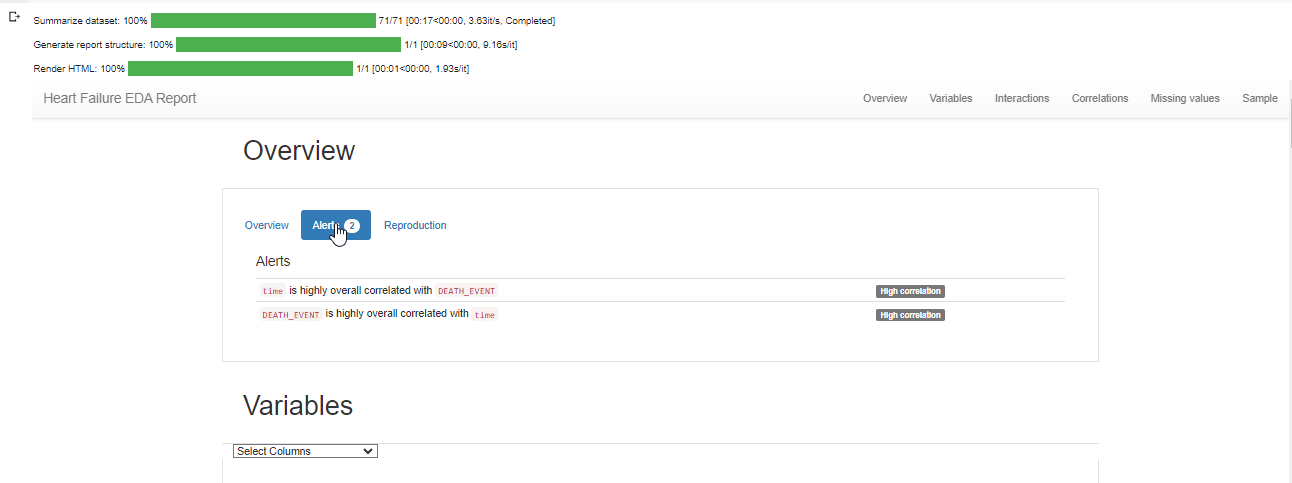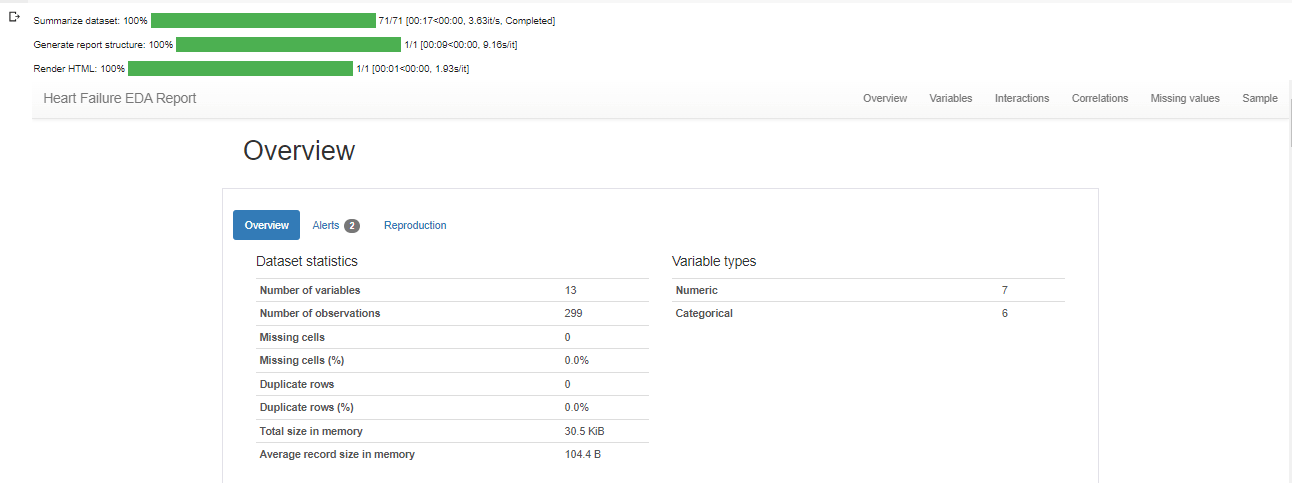
Now, let's save it as an HTML file.
profile.to_file("Heart_failure_report.html")That's it! It's as easy as that. To check out the saved report, double-click the saved HTML file in your browser.
Thank you for reading, for more guides like this follow me on;
