

Boost Your SQL Queries: Beginner’s Guide to Window Functions
Learn how to use SQL window functions in your SQL queries in this article as we explore them.


Ever wanted to do more with your data in SQL? That’s where window functions come in. They’re like special tools that help you see and work with information in new and exciting ways. Using window functions is like going deeper into your data. You can compare rows and do calculations that normal SQL commands can’t do.
In this article, I’ll walk you through how to use SQL window functions in your SQL queries.
Introduction to Window Functions
Window functions are like super tools in SQL for analyzing data. They help you do math with lots of nearby rows without mashing them all together into one.
In simpler terms, window functions let you see a “window” of data around each row and perform calculations on that specific window.
Window functions are handy tools often used with the “OVER” clause. This combo helps you specify certain data windows. As you get better at working with data and databases, getting the hang of window functions lets you pull out important info from your data more.
Window functions Default Syntax
Window functions’ syntax can differ based on the database you’re using. But, here’s a simple overview of how it generally looks:
SELECT column1, column2,
window_function(colunm3)
OVER (
[PARTITION BY partition_column]
[ORDER BY order_column]
)
AS result_column
FROM your_tableIn the above syntax:
column1,column2are the columns you want to select.window_function(column3)is the specific window function you want to apply tocolumn3.PARTITION BY partition_columndivides the result set into partitions based on the values inpartition_column.ORDER BY order_columnorders the rows within each partition using the values inorder_column.result_columnis the alias for the result of the window function.your_tableis the name of the table you're querying.
Make sure to replace the example placeholders like column1, window_function, partition_column, etc., with the actual names you’re using in your database.
Understanding Over (), Partition BY and Order by in window functions
Understanding the concepts of OVER(), PARTITION BY and ORDER BY in window functions is fundamental to using these functions in SQL. Let’s examine each of these clauses:
a. OVER(): The OVER() clause defines the window or subset of rows within which a window function operates. It specifies how you want to group and order the rows for the calculation. Without the OVER() clause, a window function would operate on the entire result set, which might not be what you want.
b. PARTITION BY: The PARTITION BY clause is used within the OVER() clause to divide the rows into groups or partitions. Window functions are then applied within each partition. It’s like creating smaller sections or groups within your data. This is helpful for performing calculations for different groups.
c. ORDER BY: The ORDER BY clause within the OVER() clause determines the order in which the rows are processed within each partition. It’s important for functions like ranking, as it defines the basis for assigning ranks or ordering the rows. This clause is critical for accurate and meaningful calculations.
In summary, here’s how these concepts work together:
You start with a table or result set.
You use the OVER() clause to specify how you want to segment the data and order it for your window function.
The PARTITION BY clause divides the data into partitions, and the ORDER BY clause specifies the order within each partition.
The window function then calculates results within each partition based on the defined order.
Dataset Preparations
In this guide, we’ll use a table named ‘dataset’. This table holds info about employees like their names, ages, departments, and salaries.

Categories of Window Functions
While SQL window functions don’t have official categories, they are often grouped into aggregate, ranking and value functions. The basic classification divides these functions based on their roles.
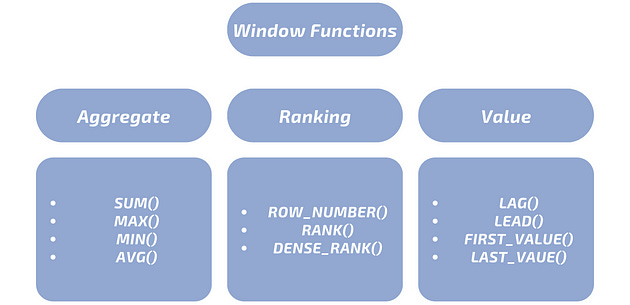
Aggregate Window Function
An aggregate window function in SQL is used to calculate an aggregate value based on a subset of rows within a defined window frame. The window frame is determined by the PARTITION BY and ORDER BY clauses specified in the OVER clause.
In simpler terms, aggregate functions such as SUM(), COUNT(), AVERAGE(), MAX(), and MIN() applied over a particular window (set of rows) are called aggregate window functions.
Let’s look at some examples of aggregate window functions.
a. Find the “avg_salary” of employees using the Over() clause
SELECT Name, Age, Department, Salary,
round(Avg(Salary) OVER(),0)
AS avg_Salary
FROM dataset;Notice that using only the Over() clause gave us a window of Avg(salary) in the entire dataset without any specific partition or ordering.
b. Now, Find the “avg_salary” of employees for each department using the PARTITION BY clause.
SELECT Name, Age, Department, Salary,
round(Avg(Salary) OVER(PARTITION BY Department),0)
AS avg_Salary
FROM dataset;
Notice that the “avg_salary” within each specific department window has the same value.
Let's see another example using the Order By and Partition By clause;
c. Find the “avg_salary” of employees for each department and order employees within a department by age.
SELECT Name, Age, Department, Salary,
round(avg(Salary) OVER( PARTITION BY Department ORDER BY Age),0)
AS avg_Salary
FROM dataset
Notice that the query result for “avg_salary” isn’t in any right order.
Hence, it’s very important that when using aggregate window functions we should be careful adding “order by” clauses
Ranking Window Function
One common use case for window functions is ranking rows based on certain criteria. Here are some of the most used ranking window functions:
a. ROW_NUMBER(): The ROW_NUMBER() function gives each row in the result set a special number. This number is based on how the rows are ordered. But, if there are rows in the same order, this function doesn’t treat them differently.
b. RANK(): The RANK() function gives a unique ranking to each different value in the data, and if there are many rows with the same value, they all get the same rank. But, it leaves gaps in the ranking sequence when there are ties.
c. DENSE_RANK(): DENSE_RANK() works like RANK(), but when there are rows with the same value, it doesn’t leave any gaps in the ranking. Instead, those rows all get the same rank.
Note: When using the ranking window functions, it’s important to always include the ORDER BY clause.
Let’s look at an example of a ranking window function.
In this example, let's Calculate the row number, rank, and dense rank of staff in our table order by salary and partition by each department.
SELECT Name, Age, Department, Salary,
ROW_NUMBER() OVER (PARTITION BY Department ORDER BY Salary DESC)
AS staff_row_numuber,
RANK() OVER(PARTITION BY Department ORDER BY Salary DESC)
AS staff_rank,
DENSE_RANK() OVER(PARTITION BY Department ORDER BY Salary DESC)
AS staff_dense_rank
FROM dataset;
The result shows that using the ROW_NUMBER() function assigns a unique number to each department, even when there are duplicate salaries like in the two “Accounting” departments. Additionally, we can observe a distinction between RANK() and DENSE_RANK() functions. In the “staff_dense_rank” column, there are no gaps between rank values, whereas in the “staff_rank” column, there are gaps in rank values after repeats (as seen in the “Accounting” entries).
Value Window Function
Value window functions in SQL are tools that let you give row values from different rows. These functions work a bit like ranking window functions, and they’re different from regular aggregate functions. The unique thing is that these value functions don’t have straightforward alternatives that don’t involve using window concepts. However, the value window functions are not as commonly used as the ranking functions.
a. LAG(): The LAG() function in SQL helps you look back at the previous row's value within a table column. It's like glancing in the rearview mirror to see what just happened. You can use it to compare data between rows and understand how things change from one row to the next.
b. LEAD(): The LEAD() function in SQL is like looking ahead to the next row's value within a table column. It helps you see what's coming up, similar to anticipating what's next on your path. This function is handy for comparing data between rows and figuring out trends or shifts as you move through the rows.
LAG() and LEAD() are great for time-series data, like tracking daily or monthly changes, and other similar tasks.
c. FIRST_VALUE(): The FIRST_VALUE() function in SQL grabs the first value in a specific column within a group of rows. It’s like picking the front item in a line of objects. This can be useful for figuring out the initial state or starting point within a group of related data.
d. LAST_VALUE(): The LAST_VALUE() function in SQL fetches the last value in a particular column within a group of rows. It's akin to selecting the item at the end of a line of things. This can be handy for understanding the final state or endpoint within a set of related data.
Let’s look at some examples of value window functions.
a. Check the LAG() and LEAD() functions in our dataset
SELECT Name, Age, Department, Salary,
LAG(Salary) OVER () AS staff_lag_sal,
LEAD(Salary) OVER() AS staff_lead_sal
FROM dataset;
Notice that the LAG() function shifts the salary values 1 row down from the top value and the LEAD() function shifts the salary values 1 row up from the last value.
SELECT Name, Age, Department, Salary,
LAG(Salary) OVER (PARTITION BY Department ORDER BY Salary DESC)
AS staff_lag_sal,
LEAD(Salary) OVER(PARTITION BY Department ORDER BY Salary DESC)
AS staff_lead_sal
FROM dataset;
Notice that with the “partition by” and “order by” clauses the LAG() function shifts the salary values 1 row down from the top value within the partition department and the LEAD() function shifts the salary values 1 row up from the last value within the partition department.
Conclusion
In this beginner’s guide to SQL window functions, we explored how they enhanced data analysis. Window functions are tools that allow you to compare, calculate, and extract insights from your data in unique ways. They enable you to look at specific sets of rows, perform calculations, and understand patterns. We covered different types of window functions: aggregate, ranking, and value functions. By mastering window functions, you can dive deeper into your data and uncover hidden insights.
Your support is invaluable
Did you like this article? Then please leave a share or even a comment, it would mean the world to me!
Don’t forget to subscribe to my YouTube account HERE, Where you will get a video explaining this article!